
정량적 위험성평가 수행은 (1) 위험요소 확인(Hazard identification), (2) 피해예측 분석(Consequence analysis), (3) 사고빈도 분석(Frequency analysis), (4) 위험성 척도 계산 및 표현(Risk measure & Presentation)의 절차로 수행한다.
금번은 위험성 척도 계산 및 표현(Risk measure & Presentation)에 대해 살펴보고자 한다.

위험성 척도 계산 및 표현(Risk measure & Presentation)
위험성 척도 계산 및 표현 개요
Risk는 손실 또는 상해의 가능성 및 크기라는 관점에서 경제적인 손실 또는 인간의 상해의 척도로서 정의할 수 있다.
손실 또는 상해의 가능성 및 크기에 관하여 일반적으로 3가지의 방법으로 표현하고 있다.
Risk indices, Individual Risk, Societal risk로 표현되며 다음과 같이 정의할 수 있다.
○ Risk indicies : 단순히 위험의 정도를 제시하는 간단한 숫자 또는 도표
○ Individual risk(IR) : 사고의 영향 범위내의 어느 지점에 있을지도 모르는 개인에 대한 위험을 표시
○ Societal risk(SR) : 사고의 영향 범위 내에 있을지도 모르는 일반 대중에 대한 위험을 표시
Risk Indices
위험지수는 간단한 숫자 또는 도표로 표시되며 절대적 또는 상대적으로 사용된다.
위험지수를 사용하는데 있어서의 한계는 첫째는 위험을 수용하거나 또는 받아들이지 않는 것에 대한 절재적인 기준이 없다는 점과 두 번째는 위험에 대한 해답이 부족하며 IR나 SR와 같은 동일한 기준이 없다는 것이다. Dow and Mond 지수와 같은 결과적인 지수는 비교적인 의미에서의 위험만을 고려하고 있다.
위험지수를 절대적인 방법으로 사용하는 예로는 Fatal accident rate(FAR), Individual hazard index(IHI), 평균 사망률 등이 있다.
○ FAR는 10^8 노출시간(Based on 1000 employees working for 50 years during their lifetime, 1 worker year = 50 work weeks/yr * (40 hrs/week) = 2,000 hrs)에 대한 계산된 치명도의 숫자이다.
○ Individual hazard index(IHI)는 특정 위험에 대한 FAR이다. 여기서 노출시간은 사람이 관련된 위험에 노출되는 실제 시간을 의미 한다. IHI에서는 최고의 위험도를 측정한다.
○ 평균 사망률은 모든 가능한 사고에 의해 일정시간당 평균 치사율(Number of fatalities per year / Total number of people in applicable population)을 의미한다. 이 평균 사망률은 Accident fatality number로도 불린다.
OSHA Incidence Rate (IR, 사고 발생률), Fatal Accident Rate (FAR, 치명적 사고율), Fatality Rate(연간 인당 사망률)에 대한 내용은 기 포스팅한 다음 링크 자료 참조
https://sec-9070.tistory.com/272
FAR vs. Fatality Rate 등
사고 및 손실 통계는 안전 프로그램이 잘 작동하는 지 그 효과를 측정하기 위해 사용된다. FAR vs. Fatality Rate 등 사고 및 손실 성과를 측정하는데 다음과 같은 지표들이 사용된다. 하기 지표들은
sec-9070.tistory.com
Individual risk
1984년 Considine은 IR를 위험원 근처의 개인에 미치는 위험이라 정의하였다. 이 정의는 개인에 미치는 상태의 특성, 상해발생 가능성 및 상해를 입을 수 있는 시간 등을 포함하고 있다. IR은 특정 장소에서 어떤 부류에 속한 개인 또는 사고의 영향을 받는 지역의 평균 개인의 위험을 측정한다. 여러 특정한 사고에서 IR의 측정치는 다르게 나타난다.
○ IR Contours는 [그림 1]과 같이 개별적인 위험의 지역적인 분포도이다. 위험등고선은 어느 특정한 장소에서 특정한 정도의 위험을 야기시킬 수 있는 사건의 예상빈도를 의미한다. 즉 그 특정 장소에 상해를 입을 수 있는 어느 특정인이 있는지 없는지에 상관없이 사건의 예방 빈도를 보여준다.
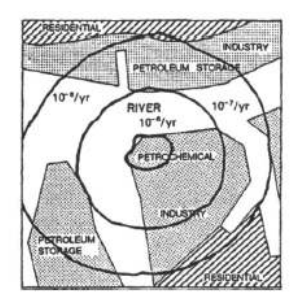
<그림 1> IR Contour
○ 최대 IR는 위험에 노출된 다수 중에서 가장 높은 수치의 위험에 노출될 수 있는 사람에 대한 IR를 말한다. 특정 단위공장의 운전원이 최대 IR에 노출된다고 할 수 있으나 위험이 가장 높은 지역에 거주하는 사람이 이에 해당될 수도 있다. 최대 IR은 위험이 가장 높은 지역에 사람을 이주시켜 그 지점에서의 IR가 얼마인지를 측정하여 작성한 IR Contour을 이용하여 결정할 수 있다. 반대로 사람이 있는 모든 장소에 대해 IR을 계산하여 최대 수치를 찾으면 결정할 수 있다
○ 평균 IR는 미리 결정한 대다수의 사람들이 모두 실제적인 위험에 놓이는 지 여부에는 상관없이 미리 결정한 사람에 대하여 평균한 IR을 의미한다. 이 위험측정은 인구에 대해 위험이 균일하게 분포되어 있을 때 유용하게 사용할 수 있으나 위험이 균일하게 분포되어 있지 않은 때에는 잘못된 결과를 가져올 수 있다.
○ 평균 IR은 어떤 활동에 대한 기간 동안 계산되거나 또는 근로 일에 대하여 평균치로 계산될 수 있다, 예를 들어 어느 작업자가 교대 근무시간 중 1시간은 반응기의 반응물을 채취 분석하는데 사용하였고 나머지 7시간은 조정실에서 근무를 하였다면 반응물 시료 채취를 하는 동안의 IR은 일일 전체 근무시간의 평균 IR보다 8배가 더 높게 된다.
가) IR 계산
IR 계산 절차는 영국화학공학회(IChemE)에서 1985년 검토한 것을 기준으로 한다. 먼저 공장 주변에 있는 IR의 계산에서 모든 사고 결과 사례(Incident outcome case)의 원인이 가산할 수 있다고 가정한다. 따라서 공장의 각 지역의 총 IR은 공장과 관련된 모든 사고 결과 사례의 IR의 합계와 같다.


사고 결과 사례 i, fi의 빈도를 계산하려면 사고 결과 및 사고 결과 사례 확률 (사고 I의 발생 빈도를 고려한 Po,i, Poc,i)이 평가되야 한다. 예를 들어, 무독성 가연성 물질(사고)는 제트 화재, 액면 화재, BLEVE, 플래시 화재, 제한되지 않은 증기운 폭발 또는 점화되지 않은 경우 안전한 분산(사고 결과)을 초래할 수 있다. 이러한 각 결과에는 이와 관련된 조건부 확률 (Po,i)이 있다.
이러한 사고 결과 중 일부는 발화원 위치 및 기상 조건에 따라 사고 결과 사례로 세분화 된다. 이러한 각 사고 결과 케이스에는 조건부 발생 확률 (Poc,i)이 있다. 이러한 관계를 평가하는 데 일반적으로 Event tree가 사용된다.
나) IR Contour와 프로파일
CPQRA에서는 시설 주변의 지리적 위치에서 IR을 추정하고 이 정보를 사용하여 Contour과 프로파일을 생성하기 위한 두 가지 계산 방법이 제시된다. 사고(Incident), 사고 결과(Incident outcome) 및 사고 결과 사례(Incident outcome case)의 연구 그룹에 대한 모든 위치에서 IR을 추정해야하는 일반적인 접근 방식이 먼저 논의된다. 점화원 및 날씨 데이터는 분석을 위한 연구 깊이에 의하여 세부 사항으로 통합 될 수 있다. 이 접근 방식은 일반적으로 S/W를 통한 계산이 필요하지만 단순화 된 결과 및 영향 모델은 그래픽 또는 수작업 계산을 사용하는 것이 가능할 수 있다. 두 번째 접근 방식은 예를 들어 기상 사례 및 점화원의 수를 제한하는 가정을 단순화하는 것으로 수작업 계산이 적합하다.
다) 일반적인 IR 계산 접근법
일반적인 IR 계산 접근방식은 방정식의 적용이 필요하며 실제 사고에 대하여 일반적인 IR 계산 접근방식을 적용하고 점화원, 기상 조건에 세부적인 처리를 통합하면 사고 결과 사례가 매우 많이 발생한다. 많은 수의 IR 계산이 필요하며 이에 따라 컴퓨터 프로그램을 사용한 계산이 요구된다.
CPQRA에서는 화학 물질이 독성과 인화성의 두가질 결과를 가진 물질인 경우 개별 위험 추정을 위해 사고 결과 사례를 정의 할 때 주의해야 한다. 그러한 화학 물질의 누출은 제한되지 않은 증기운 폭발이나 바람이 불어오는 독성 가스 누출을 초래할 수 있다. 두 사건 모두 동일한 누출 중에 발생할 수 있다.
두 가지 결과가 모두 포함 된 사고 분석은 CPQRA 책의 범위를 벗어난다.
라) 단순화된 IR 계산 접근법
위에서 설명한 접근 방식은 여러 가지 방식으로 단순화 될 수 있다. 예를 들어, 특정 연구의 목표는 개별 위험의 지리적 위치에 대한 지식을 요구하지 않을 수 있다. 그러한 IR을 계산하여 연구 목표를 달성 할 수 있다. 예를 들어, 고려중인 특정 위치에서만 위험성 평가를 요구하는 제어 건물의 여러 잠재적 위치에 대한 위험을 비교하기 위한 연구를 수행 할 수 있다. 이 경우 위에서 설명한 방법론은 관심 있는 위치에만 적용하면 계산 작업이 크게 줄어 든다. 관심 위치에 대한 개별 위험 추정치는 각 위치에서 동일한 계산이 수행되지만 고려되는 위치가 더 적기 때문에 전체 IR contour Map이 개발 된 경우 얻은 것과 정확히 동일하다. 손실되는 것은 위험의 지리적 분포에 대한 자세한 정보이다.
두 번째 단순화 된 접근 방식은 다음 가정을 기반으로 한다.
○ 모든 위험은 누출 포인트에서 발생한다.
○ 바람 분포가 균일하다 (바람이 어느 방향으로든 똑같이 불가능성이 있다.)
○ 단일 풍속 및 대기 안정성 등급을 사용할 수 있다.
○ 완화 요소는 고려되지 않는다.
○ 점화원은 균일하게 분포되어 있다 (즉, 점화 확률은 방향에 의존하지 않는다).
○ 결과 영향은 개별적으로 처리 할 수 있다. 특정 영향 지역 내의 영향 수준은 일정 하다. (예 : 같은지역 내의 IR이 동일함 100 % 사망), 특정 영향 지역을 벗어나면 영향이 발생되지 않는다.
위의 가정안에 따라 IR 계산을 하면 모든 IR Contour는 원형 형태로 Mapping되며, 단순화 된 접근 방식의 IR 계산은 신규 공장에 대한 예비 연구로 적합하다.
이외의 위험은 다음과 같다
○ 모든 위치에서 최대 값에 대한 결과를 추구하는 최대 IR
○ 시설물로 비롯된 위험에 노출된 모든 개인의 IR을 평균내어 결정된 평균 IR
○ 인구가 시설물에서 위험을 받는지 여부에 관계없이 사전에 결정된 인구에 대한 평균 IR 등이 있다.
Societal risk
어느 사고는 많은 사람에게 영향을 미칠 수 있는 잠재적인 위험을 갖고 있다. SR는 집단에 속한 사람들에 미치는 위험성을 말한다. SR은 다양한 사건의 발생 빈도 분포로 표현된다. 그러한 SR은 IR과 비슷한 용어로 표현된다. 예를 들면 SR은 특정장소 x, y에서 10명의 치사율이 발생할 가능성을 체크한다. SR의 계산에는 IR의 계산에 사용된 동일한 가능성과 결과에 대한 정보를 사용하여야 한다.
또한 SR의 계산에는 설비 주변의 사람들이 처하게 될 위험을 먼저 정의하여야 한다. 그 정의에는 인구의 형태, 예를 들면 주민, 산업체에 종사하는 근로자, 학생 수 그리고 그 위험지역에 사람들이 존재할 수 있는 가능성 또는 피해최소화 대책에 관한 요소가 포함되어야 한다.
IR 또는 SR은 동일한 사고의 발생 빈도 및 결과의 근본적인 조합을 다르게 표시할 뿐이다. IR 및 SR은 위험의 감소 대책의 장점을 평가하거나 또는 절대적인 측면에서 치명도의 허용 기준을 판단하는데 중요하다. 일반적으로 기본적인 빈도 및 결과가 동일할 지라도 재계산을 하지 않으면 어느 값에서 다른 수치를 계산할 수 없다.
SR 측정 값은 단일 숫자 측정 값, 표 형식의 숫자 집합 또는 그래픽 요약으로 표현할 수 있으며 가장 일반적인 그래픽 표현은 빈도-수 (F-N) 곡선이다. F-N 곡선은 다중 사고 사건의 빈도 분포를 나타내는 도표이며, 여기서 F는 N 명 이상의 사상자로 이어지는 모든 사건의 누적 빈도 (일반적으로 사망자 수로 표시됨)이다. F-N 곡선은 일반적으로 로그 플롯을 사용한다. 그 이유는 사망자의 빈도와 수가 종종 수십 배에 달하기 때문이다.
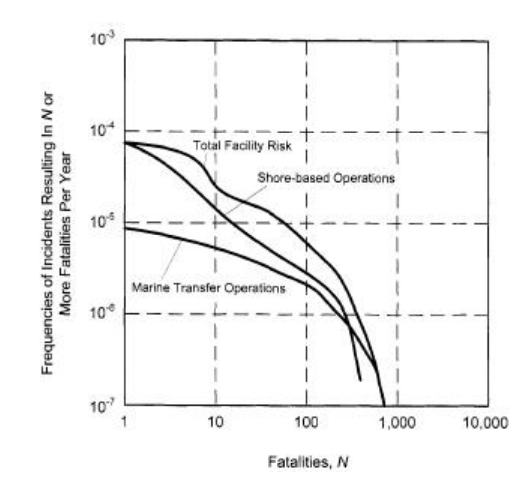
<그림 2> SR F-N Curve
IR과 SR의 차이는 다음과 같은 예를 들어 설명할 수 있다.
화학공장 근처에 있는 어느 건물에는 근무시간에 약 400명이 근무하고 이외의 시간에는 경비 혼자만이 있다고 가정한다. 만약 건물에 사고로 인하여 입게 되는 치명도가 밤과 낮 모두 동일하다면 이 건물 내에 있는 모든 개인은 동일한 정도의 위험에 처하게 된다. 이 IR은 현재 있는 사람의 숫자와는 무관하다. 즉 낮에 근무하는 400명 각 개인 및 밤에 근무하는 경비 일인에게 미치는 위험은 동일하다. 하지만 400명이 근무하는 근무시간대의 SR은 밤에 혼자 근무하다 입게 되는 위험보다 훨씬 높다.
개인적 위험과 사회적 위험 차이에 대한 세부 내용은 기 포스팅한 다음 링크 자료 참조
https://sec-9070.tistory.com/159
SR F-N Curve를 나타내는 절차는 영국화학공학회(IChemE)에서 1985년 검토한 것을 기준으로 한다. 시설물 주변의 인구에 관한 정보를 포함하여 IR의 모든 정보도 SR을 계산하는데 필요하다. IR 분석에 활용되었던 요소를 더 자세히 분석하려면 다음이 필요하다.
○ 완화 요소를 평가하기 위한 인구 유형(예 : 주거지, 사무실, 공장, 학교)에 대한 정보
○ 시간/일(time-of-day)의 영향에 관한 정보(예, 학교)
○ 일/주(day-of-week)의 영향에 관한 정보(예, 산업, 교육, 여가 시설물)
○ 완화 인자의 평가를 위해 실내에 있는 시간/인구 백분율에 관한 정보
각 사항을 고려하여 보면 인구에 관한 정보가 필요하다. 각 인구 분포에 대한 사고빈도는 총 사고빈도와 일치하는 그 인구 분포의 발생에 대한 상대적 확률과 동일하다.
가) 일반적인 SR 계산(표현) 접근법
F-N Curve의 계산 단계는 피해 영향과 빈도 분석을 통한 IR 계산과 동일하다 따라서 각 사고 결과 사례의 영향을 받는 사람의 수(인구 수)를 예측하려면 인구 자료와 결합하여야 한다.
사회적 위험 계산은 모든 사고 결과 사례의 사망을 예측해야 하기 때문에 시간이 많이 걸릴 수 있다. 사고를 사고 결과 및 사고 결과 사례로 다시 세분하여 각 기상조건, 풍향, 점화 사례 및 인구 사례를 평가하여야 한다. 사고는 기상조건 사례의 수(W), 풍향의 수(N), 점화 사례의 수(I), 인구 사례의 수(P)와 관련하여 W*N*I*P의 곱으로 분석되어 하나의 사고는 여러 사고 결과 사례(경우의 수)로 산출된다.
나) 단순화된 SR 계산(표현) 접근법
일반적인 계산 접근법에서 고려된 기후, 풍향, 인구사례의 수를 제한하여 줄이면 단순화된 SR 계산을 할 수 있지만 정확성이 떨어지게 된다.
Reference : KOSHA 연구보고서 "정량적 위험성평가(CPQRA) 방법 도입 방안 마련 연구"
'공정 및 화공안전 > 정량 위험성평가' 카테고리의 다른 글
| ERPG 및 ERPG-2 (0) | 2023.11.02 |
|---|---|
| 영국 및 네델란드의 위험성 기준(Risk Criteria) (0) | 2023.07.19 |
| 정량적 위험성평가 수행 방법(3) (0) | 2023.07.17 |
| 정량적 위험성평가의 수행 방법(2) (0) | 2023.07.17 |
| 정량적 위험성평가의 수행 방법(1) (0) | 2023.07.17 |




댓글